TCP/IP 소켓 프로그래밍(3)
01. IP주소 체계인 IPv4와 IPv6의 차이점은 무엇인가? 그리고 IPv6의 등장배경은 어떻게 되는가?
- IPv4와 IPv6의 차이점은 IP주소의 표현에 사용되는 바이트 크기에 있다.
- IPv4(Internet Protocol version 4) = 4바이트 주소체계
- IPv6(Internet Protocol version 6) = 16바이트 주소체계
- IPv6는 2010년을 전후로 IP주소가 모두 고갈될 것을 염려하여 만들어졌다.
02. 회사의 로컬 네트워크에 연결되어 있는 개인 컴퓨터에 데이터가 전송되는 과정을, IPv4의 네트워크 ID와 호스트 ID, 그리고 라우터의 관계를 기준으로 설명하여라.
- IPv4 기준의 4바이트 IP주소는 네트워크 주소와 호스트(컴퓨터를 의미함) 주소로 나뉘며, 주소의 형태에 따라서 A, B, C, D, E 클래스로 분류가 된다. 참고로 클래스 E는 일반적이지 않은, 예약되어있는 주소체계이다.
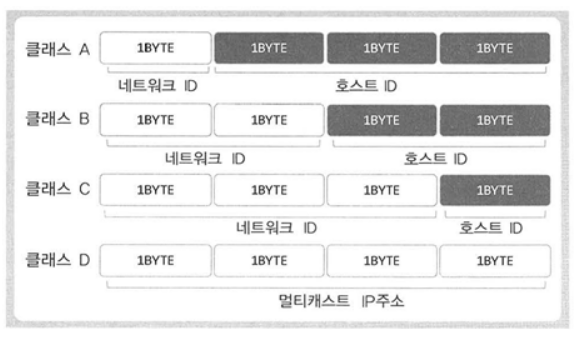
- 네트워크 주소(네트워크 ID)란 네트워크의 구분을 위한 IP주소의 일부를 말한다. 예를 들어 WWW.SEMI.COM 이라는 회사의 무대리에게 데이터를 전송한다고 가정해보자. 그런데 이 회사의 컴퓨터는 하나의 로컬 네트워크로 연결되어있다. 그렇다면 먼저 SEMI.COM의 네트워크로 데이터를 전송하는 것이 우선이다. 즉, 처음부터 4바이트 IP주소 전부를 참조해서 무대리의 컴퓨터로 데이터가 전송되는 것이 아니라, 4바이트 IP주소 중에서 네트워크 주소만을 참조해서 일단 SEMI.COM의 네트워크로 데이터가 전송된다. 그리고 SEMI.COM의 네트워크로 데이터가 전송되었다면, 해당 네트워크는 전송된 데이터의 호스트 주소(호스트 ID)를 참조하여 무대리의 컴퓨터로 데이터를 전송해준다.

- 네트워크로 데이터가 전송된다는 것은 네트워크를 구성하는 라우터(Router) 또는 스위치(Switch)로 데이터가 전송됨을 뜻한다. 라우터보다 기능적으로 작은 것을 가리켜 스위치라 부르는데, 사실상 이 둘은 같은 의미로 사용이 된다.
03. 소켓의 주소는 IP와 PORT번호 두 가지로 구성된다. 그렇다면 IP가 필요한 이유는 무엇이고, PORT번호가 필요한 이유는 또 무엇인가? 다시 말해서, IP를 통해서 구분되는 대상은 무엇이고, PORT 번호를 통해서 구분되는 대상은 또 무엇인가?
- IP는 컴퓨터를 구분하기 위한 목적으로 존재한다.
- IP만 있다면 목적지 컴퓨터로 데이터를 전송할 순 있다. 그러나 데이터를 수신해야 하는 최종 목적지인 응용프로그램에까지 데이터를 전송할 순 없다.
- 컴퓨터에는 NIC(네트워크 인터페이스 카드)이라 불리는 데이터 송수진장치가 하나씩 달려있다. IP는 데이터를 NIC을 통해 컴퓨터 내부로 전송하는데 사용된다. 그러나 컴퓨터 내부로 전송된 데이터를 소켓에 적절히 분배하는 작업은 운영체제가 담당한다. 이 때 운영체제는 PORT 번호를 활용한다.
즉, NIC을 통해서 수신된 데이터 안에는 PORT번호가 새겨져 있다. 운영체제는 이 정보를 참조해서 일치하는 PORT번호의 소켓에 데이터를 전달하는 것이다.
- 이렇듯 PORT번호는 하나의 운영체제 내에서 소켓을 구분하는 목적으로 사용된다.
- PORT번호는 16비트로 표현된다.
- 할당할 수 있는 PORT번호는 0이상 65535이하이다. 그러나 0부터 1023번까지는 '잘 알려진 PORT(Well-known PORT)'라 해서, 프로그램에 할당하기로 예약되어 있기 때문에 이 범위의 값을 제외한 다른 값을 할당해야 한다.
04. IP주소의 클래스를 결정하는 방법을 설명하고, 이를 근거로 다음 IP주소들이 속하는 클래스를 판단해보자.
- 214.121.212.102 (첫 번째 바이트 범위가 클래스C에 속함)
- 120.101.122.89 (첫 번째 바이트 범위가 클래스A에 속함)
- 129.78.102.211 (첫 번째 바이트 범위가 클래스B에 속함
- 클래스 A의 첫 번째 바이트 범위 (0이상 127이하) = 클래스 A의 첫 번째 비트는 항상 0으로 시작
- 클래스 B의 첫 번째 바이트 범위 (128이상 191이하) = 클래스 B의 첫 두 비트는 항상 10으로 시작
- 클래스 C의 첫 번째 바이트 범위 (192이상 223이하) = 클래스 C의 첫 세 비트는 항상 110으로 시작
05. 컴퓨터는 라우터 또는 스위치라 불리는 물리적인 장치를 통해서 인터넷과 연결된다. 그렇다면 라우터 또는 스위치의 역할이 무엇인지 설명해보자.
- 네트워크를 구성하려면 외부로부터 수신된 데이터를 호스트에 전달하고, 호스트가 전달하는 데이터를 외부로 송신해주는 물리적 장치가 필요하다. 이를 가리켜 라우터 또는 스위치라 하는데, 이것도 그냥 컴퓨터에 지나지 않는다. 다만 특수한 목적을 가지고 설계 및 운영되는 컴퓨터이기 때문에 라우터 또는 스위치라는 별도의 이름을 붙여준 것이다.
- 컴퓨터도 적절한 소프트웨어만 설치 및 구성하면 라우터로 동작시킬 수 있다.
06. '잘 알려진 PORT(Well-known PORT)'는 무엇이며, 그 값의 범위는 어떻게 되는가? 그리고 잘 알려진 PORT 중에서 대표적인 HTTP와 FTP의 PORT번호가 어떻게 되는지 조사해보자.
- Well-known PORT의 범위는 0부터 1023번 포트까지이다.
- HTTP 80
- FTP 21
07. 소켓에 주소를 할당하는 bind 함수의 프로토타입은 다음과 같다.
int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen);그런데 호출은 다음의 형태로 이뤄진다.
bind(serv_sock, (struct sockaddr*) &serv_addr, sizeof(serv_addr);여기서 serv_addr은 구조체 sockaddr_in의 변수이다. 그렇다면 bind 함수의 프로토타입과 달리 구조체 sockaddr_in의 변수를 사용하는 이유는 무엇인지 간단히 설명해보자.
08. 빅 엔디안과 리틀 엔디안에 대해서 설명하고, 네트워크 바이트 순서가 무엇인지, 그리고 이것이 필요한 이유는 또 무엇인지 설명해보자.
※ 인텔, AMD는 리틀 엔디안을 기준으로 정렬한다.
※ 4바이트 int형 정수 0x12345678을 저장한다고 가정했을 때
- 빅 엔디안(Big Endian)
상위 바이트의 값을 작은 번지수에 저장하는 방식

- 리틀 엔디안(Little Endian)
상위 바이트의 값을 큰 번지수에 저장하는 방식

- 네트워크 바이트 순서란
네트워크를 통해서 데이터를 전송할 때에는 통일된 기준으로 데이터를 전송하기로 약속하였으며, 이 약속을 가리켜 '네트워크 바이트 순서(Network Byte Order)'라 한다. 즉, 네트워크상으로 데이터를 전송할 때에는 데이터의 배열을 빅 엔디안 기준으로 변경해서 송수신하기로 약속하였다.
- 네트워크 바이트 순서가 필요한 이유

그림에서는 빅 엔디안 시스템에 저장된 값 0x1234를 리틀 엔디안 시스템에 전송하는데, 바이트 순서에 대한 문제를 고려하지 않고 0x12, 0x34의 순으로 데이터를 전송하고 있다. 결국 리틀 엔디안 시스템은 전송되는 순서대로 데이터를 저장한다. 때문에 전송된 값은 리틀 엔디안 입장에서는 0x1234가 아닌 0x3412가 되어버린다. 바로 이러한 문제점 때문에 네트워크를 통해서 데이터를 전송할 때에는 통일된 기준으로 데이터를 전송하기로 약속한 것이다.
09. 빅 엔디안을 사용하는 컴퓨터에서 4바이트 정수 12를 리틀 엔디안을 사용하는 컴퓨터에게 전송하려 한다. 이때 데이터의 전송과정에서 발생하는 엔디안의 변환과정을 설명해보자.
- 08번 문제를 참고할 것
10. '루프백 주소(loopback address)'는 어떻게 표현되며, 의미하는 바는 무엇인가? 그리고 루프백 주소를 대상으로 데이터를 전송하면 어떠한 일이 벌어지는가?
./hclient 127.0.0.1 9190- 127.0.0.1을 가리켜 '루프백 주소(loopback address)'라 하며 이는 컴퓨터 자신의 IP주소를 의미한다.
- 서버와 클라이언트가 하나의 컴퓨터에서 실행되는 상황을 연출하기 위해 루프팩 주소를 대상으로 데이터를 전송하였다. 물론 이를 대신해서 컴퓨터의 IP주소를 입력해도 프로그램은 동작한다. 뿐만 아니라, 서버와 클라이언트를 서로 다른 두 컴퓨터에서 각각 실행할 경우에는 이를 대신해서 서버의 IP주소를 입력하면 된다.